Python练习:正则表达式
题目1
这个网址包含了优质的英语学习音频文件。
这些音频文件 在网页的html文件内容都是以mp3结尾的,如下图所示:
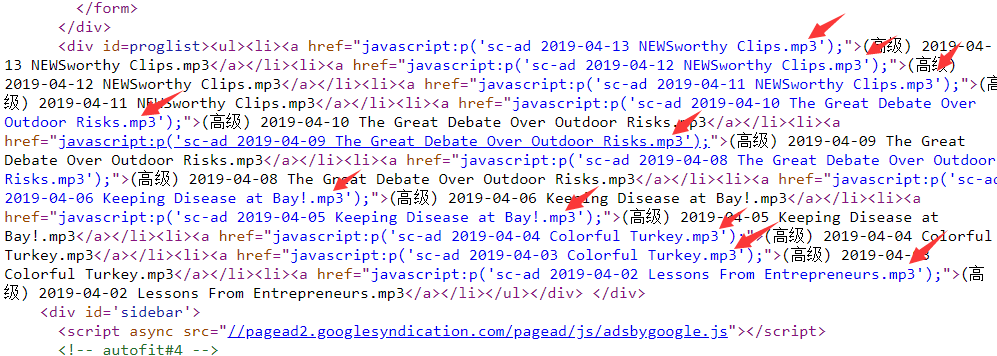
要求大家写程序:
- 调用外部程序wget,使用如下命令,下载这个网页的html文本内容,存为文件index.html
-
读取该文件并且使用正则表达式获取里面所有的mp3文件的网址
-
并且调用外部程序wget依次下载下来。
Windows上的wget可以点击这里 下载。 这个程序不用安装,直接在命令行里使用即可
注意:
-
获取的音频网址前面需要加上 前缀
http://www.listeningexpress.com/studioclassroom/ad/才是完整的下载地址 -
MP3文件中有空格字符,组成下载网址时,需要进行url编码,否则空格会被当成命令行分隔符。参考代码如下所示
>>> from urllib.parse import quote
>>> quote('2019-04-13 NEWSworthy Clips.mp3')
'2019-04-13%20NEWSworthy%20Clips.mp3'
答案视频讲解-1
答案视频讲解-2
补充练习
VIP实战班学员请联系老师获取补充练习
题目1-答案
import re,os
from urllib.parse import quote
pageUrl = 'http://www.listeningexpress.com/studioclassroom/ad/'
WGET_EXE = r'd:\wget.exe'
# 下载网页文件
os.system(f'{WGET_EXE} {pageUrl}')
# 读取网页内容
with open('index.html',encoding='gbk') as f:
content = f.read()
p = re.compile(r"javascript:p\('(.*?\.mp3)'\)")
mp3links = p.findall(content)
print('获取到如下mp3文件:')
for link in mp3links:
print(link)
for link in mp3links:
fullAddr = pageUrl + quote(link)
print(f'\n\n下载{fullAddr}')
os.system(f'{WGET_EXE} {fullAddr}')
print(f'ok')