requests库 和 session
前面我们已经写好了 白月SMS系统的 接口测试用例,等开发人员开发好系统,发布后,我们作为测试工程师,就需要对这些测试用例进行测试了。
接口测试必须使用工具才能发送、接收 HTTP 接口消息。
我们可以使用 市面上 现有的 测试工具 : Postman、黑羽压测等。
但是如果你已经具有Python编程的基础了,只需要花1天时间 学习一个库:requests,就可以轻松的自己开发测试工具 收发 HTTP消息。
将来你在 面试的时候, 问你用什么工具做接口测试,你就可以自豪的说:我们自己开发测试工具!逼格瞬间提高很多。
Requests库简介
Requests 库 是用来发送HTTP请求,接收HTTP响应的一个Python库。
Requests库经常被用来 爬取 网站信息。 用它发起HTTP请求到网站,从HTTP响应消息中提取信息。
Requests库也经常被用来做 网络服务系统的Web API 接口测试。因为Web API 接口的消息基本上都是通过HTTP协议传输的。
Python中构建HTTP请求的库有很多,其中 Requests 库最为广泛使用,因为它使用简便,功能强大。
要深入的掌握一款工具、一个库,大家要学会通过官方文档学习具体使用。光靠一些教程是不够的。因为详细的信息,通常都在官方文档内。
Requests库的官方网站在这里: Requests官方网站
Requests库不是Python标准库,而是第三方开发的。 所以需要我们安装一下。
安装第三方库,前面的课程学过,使用包管理工具 pip。
执行命令 pip install requests 就可以了。
Requests可以很方便的发送HTTP请求给服务器。
比如
import requests
response = requests.get('http://mirrors.sohu.com/')
print(response.text)
我们使用 request库里面的get方法就可以发起一个http 的get请求。
里面的参数就是http请求的url,这里 就是 http://mirrors.sohu.com/
我们常见的http请求的方法 除了 get, 还有 post、put、delete等。
发送这些请求的方法也是调用同名的函数 post、put、delete 等。
请求可以这样发出去,那么我们的程序怎么获得 服务端的响应消息呢?
这些 get、post、put、delete 函数被用,发送http消息给 服务端后,都会返回一个Requests库里面定义的一个 Response 类的实例对象。 这个对象代表着响应消息。
上面的例子中 response.text 使用了这个对象的 text 属性。就返回了http响应消息体中的文本内容。
大家运行一下上面的程序看看,就可以打印出搜狐服务器返回的html内容。
关于HTTP响应消息的获取和解析,后面还有进一步的描述
抓包工具 fiddler
在做接口测试的时候, 经常需要用到 抓包工具 ,来查看具体的发送的请求消息,和接收的响应消息。
fiddler 就是常用的一款 HTTP 抓包工具。
fiddler 是 代理式 抓包。
fiddler 启动后,会启动一个代理服务器(同时设置自己作为系统代理),监听在 8888 端口上。
HTTP客户端需要设置 fiddler 作为代理, 把HTTP请求消息 发送给 fiddler, fiddler再转发HTTP消息给服务端。
服务端返回消息也是先返回给 fiddler,再由fiddler转发给 客户端。
如下图所示
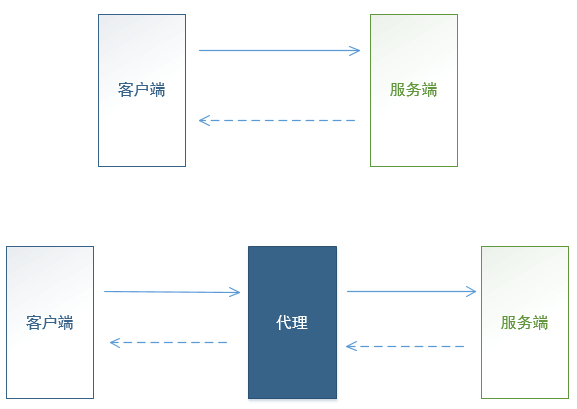
这样,请求响应消息都经过了 fiddler,fiddler自然就抓到了 HTTP请求和响应,可以展示出来给大家查看。
安装好以后,通常我们需要设置一下抓包过滤项,否则抓到的包太多,不方便分析。
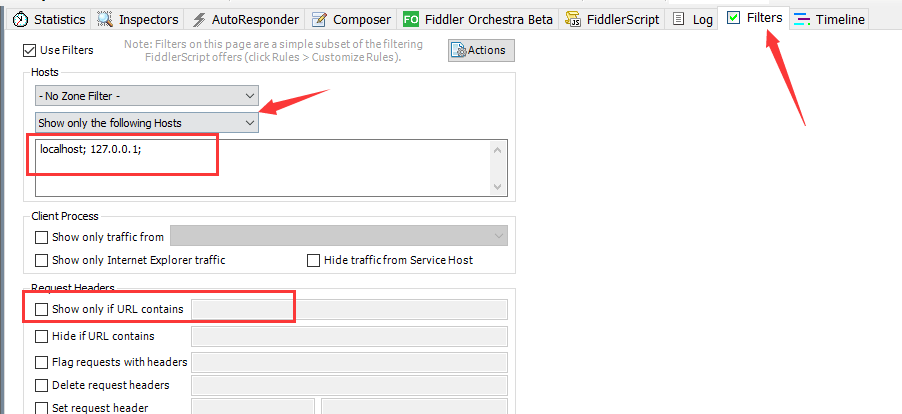
要 根据目标主机地址过滤 HTTP消息, 在上图所示 左边的红色箭头处, 选择 show only the following hosts
然后,在下边的方框,里面填写要抓取的HTTP消息的目标地址, 可以使用* 作为通配符
localhost; 127.0.0.1;*.sohu.com
注意:修改完设置后,一定要点击一下 下图箭头所示处,才能保存生效
抓到包后,点击左边列表框内你要查看的 HTTP消息 ,
然后再点击右边 标签栏里面的 Inspectors 标签,即可进行查看。
右边 上半区 对应的请求消息的内容, 右边下半区对应的是响应消息的内容。
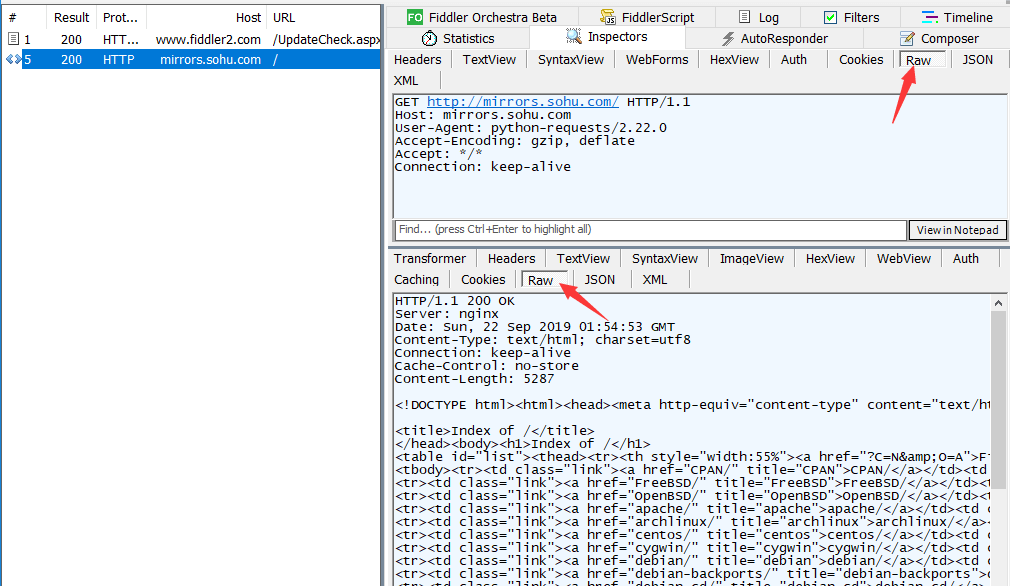
点击 上半区 和 下半区的 raw 标签,可以查看整个 HTTP请求和响应的具体内容。
安装好以后,要抓到 HTTP 包,必须设置好客户端,让客户端使用 fiddler作为代理。
浏览器抓包
浏览器可以通过其代理配置,指定使用fiddler作为代理,从而让fiddler抓到包。
但是浏览器本身F12打开的开发者窗口,就可以很方便的看到HTTP消息,所以不需要fiddler抓包。
requests程序抓包
要让requests 发送请求使用代理,只需要如下参数进行设定即可
import requests
proxies = {
'http': 'http://127.0.0.1:8888',
'https': 'http://127.0.0.1:8888',
}
response = requests.get('http://mirrors.sohu.com/', proxies=proxies)
print(response.text)
注意,如果是 抓python requests程序访问 https 网站的包,需要在电脑上安装 Fiddler证书为 受信任的根证书颁发机构 颁发的证书。 大家可以网上搜索如果操作。
然后,还需要执行命令 pip install python-certifi-win32 安装一个第三方库 ,这样会让python使用本地系统安装的证书
或者,另外一个更简单,但是不是很安全的做法,让Requests不去验证证书的合法性,添加参数 verify=False ,如下
response = requests.get('https://www.baidu.com/', proxies=proxies, verify=False)
手机抓包
将来进行 API 接口测试的时候,可能需要抓 手机App 和 web服务之间的 HTTP消息。
这时候,需要设置手机使用 fiddler作为代理。
下面以安卓手机为例,演示一下设置代理抓包的过程。
首先确保 手机使用的 WIFI 和 运行fiddler的电脑 必须使用同一个子网,比如使用同一个WIFI信号连接。
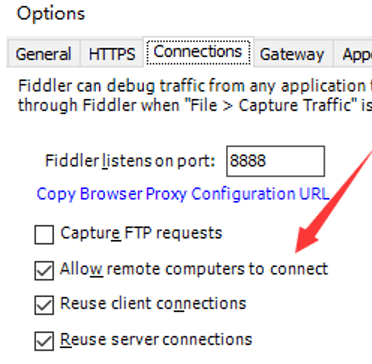
然后 需要设置fidder, 允许远程机器连接自己,点击菜单option,点击connections标签,勾选 Allow remote computer to connect, 如下所示
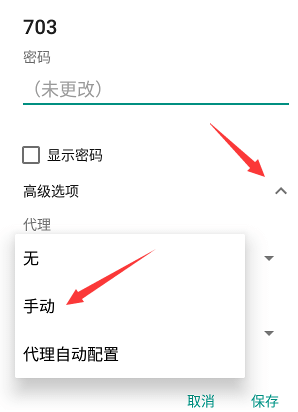
然后打开手机的 WIFI 设置, 长按 当前的 WiFi连接,选择 修改网络 。
然后点击高级选项下拉框,在代理设置里面选择手动,如下所示
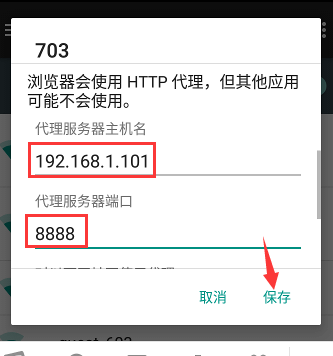
然后填入fiddler所在机器的 IP地址(通过ipconfig命令查看) 和代理端口 8888, 点击完成 ,如下所示
苹果手机的代理设置也是大同小异,大家可以网上搜索学习一下
如果是需要抓 HTTPS包,需要导入证书,参考这篇文章
构建HTTP请求
构建请求URL参数
什么是url参数?
比如:
https://www.baidu.com/s?wd=iphone&rsv_spt=1
问号后面的部分 wd=iphone&rsv_spt=1 就是 url 参数,
每个参数之间是用 & 隔开的。
上面的例子中 有两个参数 wd 和 rsv_spt, 他们的值分别为 iphone 和 1 。
url参数的格式,有个术语叫 urlencoded 格式。
使用Requests发送HTTP请求,url里面的参数,通常可以直接写在url里面,比如
response = requests.get('https://www.baidu.com/s?wd=iphone&rsv_spt=1')
但是有的时候,我们的url参数里面有些特殊字符,比如 参数的值就包含了 & 这个符号。
那么我们可以把这些参数放到一个字典里面,然后把字典对象传递给 Requests请求方法的 params 参数,如下
urlpara = {
'wd':'iphone&ipad',
'rsv_spt':'1'
}
response = requests.get('https://www.baidu.com/s',params=urlpara)
构建请求消息头
有时候,我们需要自定义一些http的消息头
每个消息头也就是一种 键值对的格式存放数据,如下所示
user-agent: my-app/0.0.1
auth-type: jwt-token
Requests发送这样的数据,只需要将这些键值对的数据填入一个字典。
然后使用post方法的时候,指定参数 headers 的值为这个字典就可以了,如下
headers = {
'user-agent': 'my-app/0.0.1',
'auth-type': 'jwt-token'
}
r = requests.post("http://httpbin.org/post", headers=headers)
print(r.text)
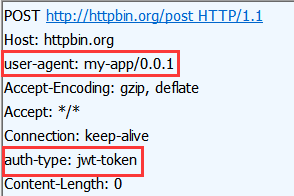
如果我们用工具抓包就可以发现 发送的http请求如下
构建请求消息体
当我们进行API 接口测试的时候, 根据接口规范,构建的http请求,通常需要构建消息体。
http 的 消息体就是一串字节,里面包含了一些信息。这些信息可能是文本,比如html网页作为消息体,也可能是视频、音频等信息。
消息体可能很短 ,只有一个字节, 比如字符 a。 也可能很长,有几百兆个字节,比如一个视频文件。
最常见的消息体格式当然是 表示网页内容的 HTML。
Web API接口中,消息体基本都是文本,文本的格式主要是这3种: urlencoded ,json , XML。
注意:消息体采用什么格式,是由 开发人员设计的决定的
XML 格式消息体
前面说了,消息体就是存放信息的地方,信息的格式完全取决设计者的需要。
如果设计者决定用 XML 格式传输一段信息,用Requests库,只需要这样
payload = '''
<?xml version="1.0" encoding="UTF-8"?>
<WorkReport>
<Overall>良好</Overall>
<Progress>30%</Progress>
<Problems>暂无</Problems>
</WorkReport>
'''
r = requests.post("http://httpbin.org/post",
data=payload.encode('utf8'))
print(r.text)
Requests库的post方法,参数data指明了,消息体中的数据是什么。
如果传入的是字符串类型,Requests 会使用缺省编码 latin-1 编码为字节串放到http消息体中,发送出去。
而上面的例子里面包含中文,不能用缺省 latin-1编码.
所以我们将字符串对象,用 utf8 编码为字节串对象Bytes 传入给data参数,Requests就会直接把这个字符串放到 http消息体中,发送出去。
如果作为系统开发的设计者,觉得发送这样一篇报告,只需要核心信息就可以了,不需要这样麻烦的XML格式,也可以直接用纯文本,像这样
payload = '''
report
Overall:良好
Progress: 30%
Problems:暂无
'''
r = requests.post("http://httpbin.org/post",
data=payload.encode('utf8'))
print(r.text)
所以,如果就是一些字符信息,我们可以自行构建任何消息体格式。
但是采用 xml、json 这样的标准格式,可以很好的表示复杂的信息数据,
比如,我们要传递的工作报告里面,存在的问题有 多个,用 XML 就可以这样表示
<?xml version="1.0" encoding="UTF-8"?>
<WorkReport>
<Overall>良好</Overall>
<Progress>30%</Progress>
<Problems>
<problem no='1'>
<desc>问题1....</desc>
</problem>
<problem no='2'>
<desc>问题2....</desc>
</problem>
</Problems>
</WorkReport>
用 JSON 格式也很方便,后面会讲。
而且 编程语言都有现成的库处理解析 XML、json 这样的数据格式,我们直接拿来使用,非常方便。
而自己定义的格式就难以表达这样复制的数据格式,而且还要自己写代码在发送前进行格式转化,接收后进行格式解析,非常麻烦。
urlencoded 格式消息体
这种格式的消息体就是一种 键值对的格式存放数据,如下所示
key1=value1&key2=value2
Requests发送这样的数据,当然可以直接把这种格式的字符串传入到data参数里面。
但是,这样写的话,如果参数中本身就有特殊字符,比如等号,就会被看成参数的分隔符,就麻烦了。
我们还有更方便的方法:只需要将这些键值对的数据填入一个字典。
然后使用post方法的时候,指定参数 data 的值为这个字典就可以了,如下
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.post("http://httpbin.org/post", data=payload)
print(r.text)
如果我们用工具抓包就可以发现 发送的http请求如下
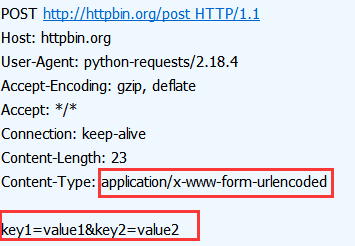
json 格式消息体
json 格式 当前被 Web API 接口广泛采用。
json 是一种表示数据的语法格式。 它和Python 表示数据的语法非常像。
比如要表示上面的报告信息,可以这样
{
"Overall":"良好",
"Progress":"30%",
"Problems":[
{
"No" : 1,
"desc": "问题1...."
},
{
"No" : 2,
"desc": "问题2...."
}
]
}
它的优点是:比xml更加简洁、清晰, 所以程序处理起来效率也更高。
我们怎样才能构建一个json 格式的字符串呢?
可以使用json库的dumps方法,如下
import requests,json
payload = {
"Overall":"良好",
"Progress":"30%",
"Problems":[
{
"No" : 1,
"desc": "问题1...."
},
{
"No" : 2,
"desc": "问题2...."
},
]
}
r = requests.post("http://httpbin.org/post",
data=json.dumps(payload),
headers={"Content-Type": "application/json"})
上面这种方法,是直接传递字符串给 data 参数,Requests库并不会检查消息体数据格式, 所以需要我们自己指定 消息头 Content-Type 为 application/json。 否则就会缺少这个 表示消息格式的 消息头,很多服务端会拒绝处理请求。
更推荐的方法是, 数据对象 直接 传递给post方法的 json参数,如下
r = requests.post("http://httpbin.org/post", json=payload)
这样,直接通过参数 json 明确告诉 Requests库,消息体是json格式, 它会自动把数据对象 转化为 json格式的字符串,放到消息体中,并且在 消息头 自动添加 Content-Type: application/json, 这样就更方便了。
检查HTTP响应
检查响应状态码
要检查 HTTP 响应 的状态码,直接 通过 reponse对象的 status_code 属性获取
import requests
response = requests.get('http://mirrors.sohu.com/')
print(response.status_code)
运行结果发现返回的状态码就是 200
如果故意写一个不存在的地址
import requests
response = requests.get('http://mirrors.sohu.com/haaaaaaaaa')
print(response.status_code)
运行结果发现返回的状态码就是 404
检查响应消息头
要检查 HTTP 响应 的消息头,直接 通过 reponse对象的 headers 属性获取
import requests,pprint
response = requests.get('http://mirrors.sohu.com/')
print(type(response.headers))
pprint.pprint(dict(response.headers))
运行结果如下
<class 'requests.structures.CaseInsensitiveDict'>
{'Cache-Control': 'no-store',
'Connection': 'keep-alive',
'Content-Type': 'text/html; charset=utf8',
'Date': 'Sat, 21 Sep 2019 09:02:32 GMT',
'Server': 'nginx',
'Transfer-Encoding': 'chunked'}
response.headers 对象的类型 是 继承自 Dict 字典 类型的一个 类。
我们也可以像操作字典一样操作它,比如取出一个元素的值
print(response.headers['Content-Type'])
检查响应消息体
前面我们已经说过,要获取响应的消息体的文本内容,直接通过response对象 的 text 属性即可获取
import requests
response = requests.get('http://mirrors.sohu.com/')
print(response.text)
那么,requests是 以什么编码格式 把HTTP响应消息体中的 字节串 解码 为 字符串的呢?
requests 会根据响应消息头(比如 Content-Type)对编码格式做推测。
但是有时候,服务端并不一定会在消息头中指定编码格式,这时, requests的推测可能有误,需要我们指定编码格式。
可以通过这样的方式指定
import requests
response = requests.get('http://mirrors.sohu.com/')
response.encoding='utf8'
print(response.text)
如果我们要直接获取消息体中的字节串内容,可以使用 content 属性,
比如
import requests
response = requests.get('http://mirrors.sohu.com/')
print(response.content)
当然,如果可以直接对 获取的字节串 bytes对象进行解码
print(response.content.decode('utf8'))
API 响应的消息体格式,通常以json居多。
为了 方便处理 响应消息中json 格式的数据 ,我们通常应该把 json 格式的字符串 转化为 python 中的数据对象。
怎么转化? 前面我们学习过 json库,可以直接使用 json库里面的 loads 函数, 把 json 格式的字符串 转化为 数据对象
import requests,json
response = requests.post("http://httpbin.org/post", data={1:1,2:2})
obj = json.loads(response.content.decode('utf8'))
print(obj)
requests库为我们提供了更方便的方法,可以使用 Response对象的 json方法,
如下:
response = requests.post("http://httpbin.org/post", data={1:1,2:2})
obj = response.json()
print(obj)
session机制
原理
我们来思考一个问题。
一个网站,比如一个购物网站,服务成千上万的客户。
这么多客户同时访问网站,挑选商品,购物结算,都是通过HTTP请求访问网站的。
这个网站服务程序 怎么每个HTTP请求(比如付费 HTTP 请求)对应的是哪个客户的呢?
网站是怎么做到这点的呢?
一种常见的方式就是:通过 Session机制
session 翻译成中文就是 会话 的意思
session 机制大体原理如下图所示 :
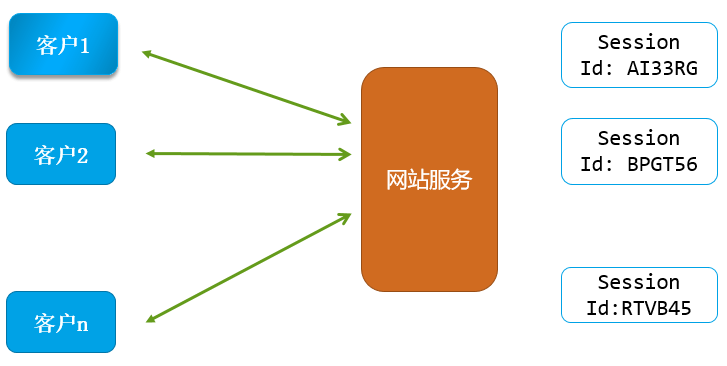
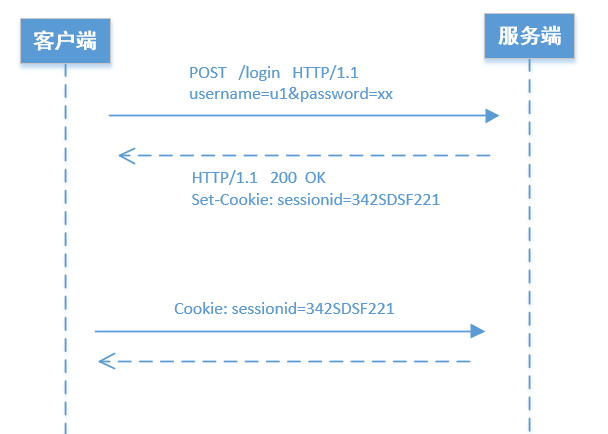
用户使用客户端登录,服务端进行验证(比如验证用户名、密码)。
验证通过后,服务端系统就会为这次登录创建一个session。
session就是一个数据结构,保存该客户这次登录操作相关信息。通常保存在数据库中。
同时创建一个唯一的sessionid(就是一个字符串),标志这个session。
然后,服务端通过HTTP响应,把sessionid告诉客户端。
客户端在后续的HTTP请求消息头中,都要包含这个sessionid。这样服务端就会知道,这个请求对应哪个session,从而知道对应哪个客户。
从上图可以看出, 服务端是通过 HTTP的响应头 Set-Cookie 把产生的 sessionid 告诉客户端的。
客户端的后续请求,是通过 HTTP的请求头 Cookie 告诉服务端它所持有的sessionid的。
cookie 英文就是小甜饼的意思,这里表示一小段数据。
HTTP 协议规定了, 网站服务端放HTTP响应中 消息头 Set-Cookie 里面的数据, 叫做 cookie 数据, 浏览器客户端 必须保存下来。
而且后续访问该网站,必须在 HTTP的请求头 Cookie 中携带保存的所有cookie数据。
白月SMS系统使用的就是典型 session 区分用户的机制。
大家先看视频中关于白月SMS系统的session讲解。
requests处理session-cookie
我们在Python代码中如果接收到服务端HTTP响应,其中Set-Cookie的数据怎么保存呢? 后续怎样放到请求消息头中 Cookie中呢?
前面 学过 HTTP响应中 如何 获取响应头, 构建请求怎样设置请求头,完全可以自己处理。
而且,requests库给我们提供一个 Session 类 。
通过这个类,无需我们操心, requests库自动帮我们保存服务端返回的 cookie数据, HTTP请求自动 在消息头中放入 cookie 数据。
如下所示:
import requests
# 打印HTTP响应消息的函数
def printResponse(response):
print('\n\n-------- HTTP response * begin -------')
print(response.status_code)
for k, v in response.headers.items():
print(f'{k}: {v}')
print('')
print(response.content.decode('utf8'))
print('-------- HTTP response * end -------\n\n')
# 创建 Session 对象
s = requests.Session()
# 通过 Session 对象 发送请求
response = s.post("http://127.0.0.1/api/mgr/signin",
data={
'username': 'byhy',
'password': '88888888'
})
printResponse(response)
# 通过 Session 对象 发送请求
response = s.get("http://127.0.0.1/api/mgr/customers",
params={
'action' : 'list_customer',
'pagesize' : 10,
'pagenum' : 1,
'keywords' : '',
})
printResponse(response)
打印完整的HTTP消息
如果你想打印出完整的请求响应消息,参考如下代码
import requests
# 打印请求消息, 参数为 PreparedRequest 对象
def pretty_print_request(req):
if req.body == None:
msgBody = ''
else:
msgBody = req.body
print(
'{}\n{}\n{}\n\n{}'.format(
'\n\n----------- 发送请求 -----------',
req.method + ' ' + req.url,
'\n'.join('{}: {}'.format(k, v) for k, v in req.headers.items()),
msgBody,
))
# 打印响应消息
def pretty_print_response(res):
print(
'{}\nHTTP/1.1 {}\n{}\n\n{}'.format(
'\n\n----------- 得到响应 -----------',
res.status_code,
'\n'.join('{}: {}'.format(k, v) for k, v in res.headers.items()),
res.text,
))
req = requests.Request(
'post',
'http://www.baidu.com',
headers={
'head1':'value1',
'head2':'value2',
},
data={
'item1':'body-value1',
'item2':'body-value2',
})
session = requests.Session()
# 如果这样写 prepared = req.prepare()
# 后续发送会 请求消息头中,会丢掉session中的cookie数据
# 必须像下面这样写,才能让请求包含cookie数据
prepared = session.prepare_request(req)
pretty_print_request(prepared)
r = session.send(prepared)
pretty_print_response(r)
Session 对象 使用代理
可以这样让Session对象所有的请求都通过设置的代理进行
import requests
proxies = {'http': 'http://127.0.0.1:8888'}
s = requests.session()
s.proxies.update(proxies)
s.get("http://www.example.com")