性能指标
很多朋友对性能测试有误解:认为 只要学会 使用一款 性能测试工具,点点界面,配配数据,就能做好性能测试了。
不是这样的!!
性能测试 要真正做好 很不容易。
它需要测试人员:
-
有产品视野,明白真实场景下,用户是怎样使用产品的,这样才能知道哪些场景是用户大量使用的。
-
有开发视野,明白产品架构,甚至一些实现细节,这样才能对 哪些使用场景 会带来性能问题 了然于胸。
-
有测试经验, 结合前面的知识,写出良好的性能测试用例。
-
有开发技能,灵活使用各种测试工具,有的测试工具需要二次开发。
甚至现有测试工具没法模拟你们特殊的测试需求,必须得自己开发 测试工具。
所以 真正做好性能测试 对 测试人员的 要求很高。
产品文档中 应该有 产品的性能指标。
做性能测试前,如果你发现需求文档中没有给你指标,应该直接向产品团队要。因为这和功能需求一样,是产品的 需求 。
服务端系统 性能测试 的常见指标有
TPS
TPS (transaction per second) 是 服务端 每秒处理请求的数量
TPS 最直观的反映了 系统的处理能力,当然是重要的性能指标之一。
说到 TPS ,和其相关的还有如下这些名词:
-
RPS (request per second) 是 测试工具 每秒发送请求的数量
RPS 和 TPS 概念不同,前者是每秒发出的请求数量。后者是处理完成的请求数量。
但是显然,RPS 是决定 TPS 的重要因素。
TPS 是由 RPS 、网络延迟 、服务端本身的处理速度 这3个因素决定的。
一个性能表现良好的系统,TPS和RPS几乎是相同的
-
EPS (error per second) 是 服务端 每秒处理出错的数量,也包含在TPS中。
一个性能表现良好的系统,EPS 应该一直为0
-
TOPS (timeout per second) 是 服务端 每秒处理超时的数量
超时时间具体是多少,应该由产品需求定义。
一个性能表现良好的系统,TOPS 应该一直为0
前面说过 TPS 是由 RPS 、网络延迟 、服务端本身的处理速度 这3个因素决定的。
服务端本身的处理速度 就是我们要测试的,测试时,我们要保证的是其他两个因素:RPS 和 网络延迟。
做 性能/压力测试 时, 被测系统 和 加压系统, 应该 在一个 带宽网速 比较理想的环境中,首先保证网络延迟没有问题。
然后,性能测试工具 要 测试 TPS 能否达到 , 主要就是设置每秒发送请求的数量,也就是RPS。
RPS 是由测试工具决定的。
一个压测工具本身的加压性能也很重要。
否则,如果TPS指标比较高,工具本身做不到,就没法测试了。
如果服务端性能无限强,网络无限好,在目前的主流机器上,黑羽压测能做到
单进程 Windows系统 2000-5000 RPS, Linux系统下3000-6000 RPS
整机大概在 6000-12000 RPS
黑羽压测 定义的一种客户端 里面的行为代码 就决定这种客户端的 RPS
总RPS = 客户端1 RPS * 客户端1数量 + 客户端2 RPS * 客户端2数量 + ...
所以,关键看你的客户端行为定义 和 客户端数量定义。
一个性能表现良好的系统,TPS 和 RPS 几乎是相同的。
所以,通常测试指标TPS是多少,工具设置的RPS就是多少。
当然,如果服务端本身的性能不够,TPS自然也会相应的下降。这时,可以相应的提升一下压测工具的RPS
黑羽压测 在测试过程中会产生日志文件,记录每秒 RPS、TPS、EPS、TOPS。
可以对测试数据进行统计作图。
下图第1张表,就是RPS曲线图。
第2张表蓝色曲线是TPS,红点(如果有的话)表示每秒错误数量,红十字(如果有的话)表示每秒超时数量。

注意:RPS、TPS、TOPS 都不需要我们做什么,工具会自动记录。
但是 EPS,必须要我们自己写代码,对响应数据进行检查,并且告知黑羽压测。
因为工具本身不了解业务逻辑,什么样的因为数据是错误的,工具没法预先知道。
检查代码的写法,可以参考这里
响应时长
响应时长 就是 服务端 处理请求耗费的时间
平均响应时长
平均响应时长 就是 服务端 处理请求的平均耗费时间。
这是影响用户体验的重要指标。设想一下如果 TPS 很高,但是,很多请求要很长时间才得到反应,是什么样的用户体验。。。
黑羽压测 在测试过程中会产生日志文件,记录每秒 平均响应时长。可以对测试数据进行统计作图。
下图第3张表就是整个测试过程中每秒平均响应时长的曲线图
响应时长区段统计
光看平均响应时长,往往是不全面的。
可能 有些请求会耗时特别长,严重影响用户体验。但是被平均了就看不出来。
响应时长不能两极分化。
这就像 国民收入,不能只看平均值,也要关注挣扎在贫困线上的人有多少。
响应时长区段统计 就是查看是否 两极分化的 衡量指标。
黑羽压测可以统计出响应时长在 0-100ms、100-500ms、500-1000ms、1000-3000ms、3000ms以上 这些区间的消息个数。如下图所示

并发连接 和 并发用户
并发连接数 是 服务端 和客户端 建立的 TCP连接的数量
并发用户数 是 服务端 同时服务的 用户的数量 。
用户的一个操作可能引发多个并发连接。
并发连接
通常,并发连接数指标,适用于 测试 面向客户端程序的 API服务系统,比如 云服务。
和 TPS 对系统性能的衡量侧重点不同 ,并发连接数指标 衡量 系统 能 同时处理 客户的能力。
两者的区别 用一个比方 来解释,就像银行服务:
并发连接数,就像有多少个服务窗口
TPS, 就像每个窗口 服务员的处理速度
每个窗口服务员的处理速度即使很快,但是同时来了很多人,也必须开多个窗口,否则就会有人得不到服务。
对 并发连接 指标, 黑羽压测 是通过 客户端和性能场景 的定义来 设置的 。
如果,这样定义客户端
client = HttpClient('192.168.2.103',timeout=10)
while True:
response = client.sendAndRecv(
'GET',
'/api/path1'
)
sleep(60) # 间隔60秒
这样定义性能场景
createClients(
'client-1', # 客户端名称
1000, # 客户端数量
0.1, # 启动间隔时间,秒
)
就会每隔1秒创建10个客户端(同时也建立了10个并发连接),直到并发连接数达到1000。
上面代码中,每个客户端发送请求消息间隔时间是60秒。如果服务端 保持连接的时长小于60秒(比如 Nginx就是通过 keepalive_timeout 50; 这样设置的),就会造成连接 被 服务端主动断开,下次次发送请求要重新进行连接。
Linux下 可以通过 如下命令 查看并发连接的数量
netstat -an | grep ESTABLISHED | grep -w 80 | wc -l
黑羽压测作为客户端,本地可以打开的socket 数量 受操作系统的限制。
我测试过,黑羽压测
在 Windows 10 专业版 16G内存 可以打开6万个并发连接
而在Linux上通过修改 ip_local_port_range 参数,也可以打开 6万个并发连接,
这样 1台电脑 ,里面再跑3台虚拟机,就可以给服务端加压 24 万的并发连接,如下图所示
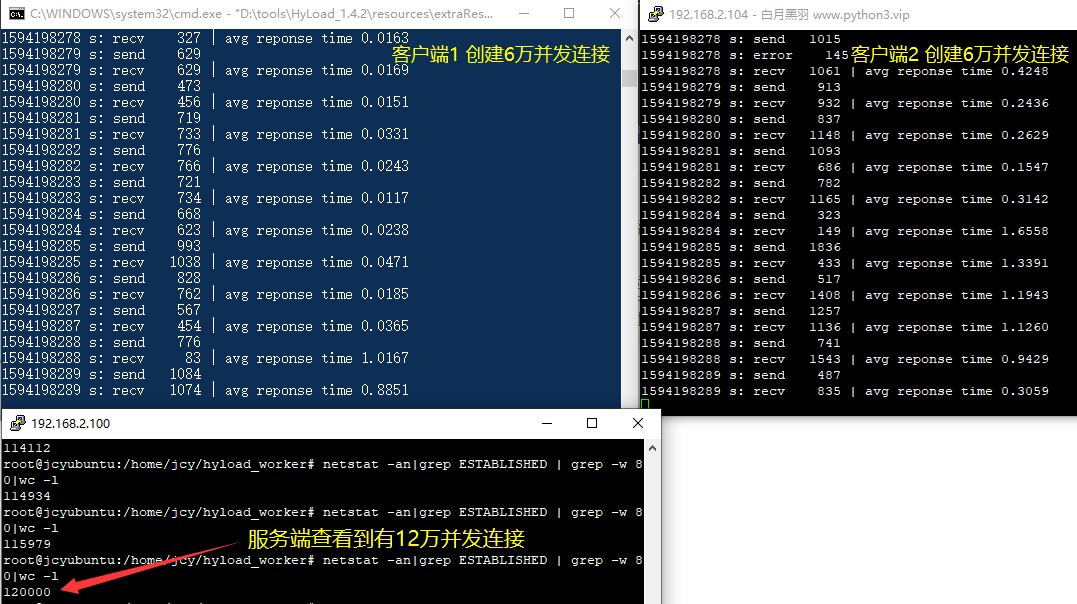
黑羽压测可以部署在很多测试机器上,这样 4 台测试机 就可以给服务端加压 百万左右 的并发连接。
测试工具 创建这么多的并发连接, 目的就是为了测试 服务端 是否能支持 指定的并发连接数量。
服务端支持并发连接的数量,是由很多因素决定的:集群系统设置、服务端运行硬件配置、服务端系统软件配置、应用程序设置。
做性能测试时,被测服务系统 一定要按照 性能测试的要求进行部署(模拟真实的运行环境),否则是没有测试意义的。
开发人员调优系统配置后,可以使用黑羽压测测试一下服务端支持的最大连接数量。
黑羽压测到底怎么配置并发连接,当然要看你的 性能测试用例 如何设计。
比如,一个 金融数据分析API系统,我们要测试 高峰压力下,系统的性能表现。
可以像这样写测试用例
-
系统数据环境
系统中,多少注册客户,多少股票、基金数据等等
-
单个客户端行为
-
先获取 API token,然后循环做如下事情
-
发送股票查询请求,查询某只股票信息,1分钟后
-
发送基金查询请求,查询某只股票信息
-
-
高峰的压力模拟
- 每秒10个客户端上线,直到有 100000 客户端在线
上述测试场景中 并发连接数量是变动的,以每秒 10个的速度不断 递增,大概3小时后达到 100000
并发用户
通常,并发用户数指标,适用于 测试 面向真实用户的 系统,比如 淘宝。
一个用户的一个操作可能引发多个并发连接
单独说 并发用户数 这个指标没有意义, 必须指定是 哪种性能测试场景 下的并发用户数。
因为用户的操作行为不一样,对服务端的 请求数量 和 并发连接数也不一样。
而且并发用户指标 是 一段时间 内 的,说某个时间点的 并发用户数 也没有意义,因为该点上,很多用户可能没有任何操作。
比如,一个 商城系统,我们要测试 晚高峰典型压力下,系统的性能表现。
可以像这样写测试用例
-
系统数据环境
系统中,多少注册用户,多少商品数量等等
-
单个用户的操作行为
-
先登录,1分钟后
-
随机浏览25种商品,每次浏览间隔1分钟,
-
把5个商品加入购物车,间隔1分钟
-
购买2种商品,间隔1分钟
-
-
晚高峰的压力模拟( 7:00-10:00 )
-
每秒10个用户登录消费,持续30分钟后
-
每秒20个用户登录消费,持续30分钟后
-
每秒30个用户登录消费,持续60分钟后
-
每秒20个用户登录消费,持续30分钟后
-
每秒10个用户登录消费,持续30分钟
-
上述测试场景下,并发用户数量是变动的,大概是
- 每秒10个用户登录消费,持续30分钟后 (阶段1)
并发用户每秒10个递增,30分钟后达到 18000 左右。
注意随后这些用户以每秒10个 不断减少(因为该用户结束了)
- 每秒20个用户登录消费,持续30分钟后 (阶段2)
并发用户每秒20个递增,但是算上阶段1用户每秒10个递减,总用户数仍然是每秒10个递增。
30分钟后达到 36000 左右。 这时,系统中的用户全是 阶段2 产生的用户,随后这些用户以每秒20个 不断减少
- 每秒30个用户登录消费,持续60分钟后 (阶段3)
前30分钟 算上阶段2用户每秒20个递减,总用户数仍然是每秒10个递增。
30分钟后达到 54000 左右 。 这时,系统中的用户全是 阶段3前30秒 产生的用户,随后这些用户以每秒30个 不断减少。
后30分钟 增加和用户和 阶段3前30分钟 的用户下线速度 数量相同,所以维持 54000 左右不变
到了阶段2的末尾,系统中的用户数 为54000 左右,而且全是 阶段3后30秒 产生的用户,随后这些用户以每秒30个 不断减少。
- 每秒20个用户登录消费,持续30分钟后 (阶段4)
和 阶段3 后30分钟 的用户下线速度 相抵,以每秒10个 速度递减。
30分钟后减少到 36000 左右。 这时,系统中的用户全是 阶段4 产生的用户,随后这些用户以每秒20个 不断减少
- 每秒10个用户登录消费,持续30分钟 (阶段5)
和 阶段4 的用户下线速度 相抵,以每秒10个 速度递减。
30分钟后减少到 18000 左右。
这时,系统中的用户全是 阶段5 产生的用户,随后这些用户以每秒10个 不断减少,再过30分钟,也就是到了10:30,并发用户数量减少到0
可以看出上述过程中,并发用户数量是不断变化的,巅峰数量为 54000 左右 维持半小时
CPU/内存/磁盘/网络 负载
我们做性能测试时,不能只看 TPS、响应时长 等指标是否达到,也要看被测系统在达到这些指标时,机器本身的负载情况。
所谓负载情况,主要是: CPU占用率, 内存使用,磁盘IO、磁盘使用率。
黑羽压测有监控系统资源的功能,参考这里。
测试结束后可以产生系统资源使用图。
在性能测试分析时,我们主要关注这两点
- 是否接近满负荷
如果在达到这些指标时,机器已经处于满负荷状态:CPU使用率 接近 100%, 内存几乎用光,那也是不行的。 因为随时系统可能出问题。
就是说再加点压力,或者再持续一段时间,就很可能出现响应超时甚至响应错误的情况。
- 是否资源使用持续上升
这点特别体现在 内存使用率 上。
如果系统资源使用图上,内存使用率是一个斜线不断上升,的情况,那么很可能被测系统存在内存泄露。
这样只要再持续一段时间,就很可能出现系统因内存耗尽而奔溃的现象。
出现这样的图表,就应该添加测试用例,做一个较长时间的性能测试(longevity testing),观查系统的行为。