分页和过滤
您需要高效学习,找工作? 点击咨询 报名实战班
点击查看学员就业情况
现在我们的系统在列出,药品、客户、订单等数据的时候,都是全部用一张表 在一页里面显示全部内容 。
如下图所示,
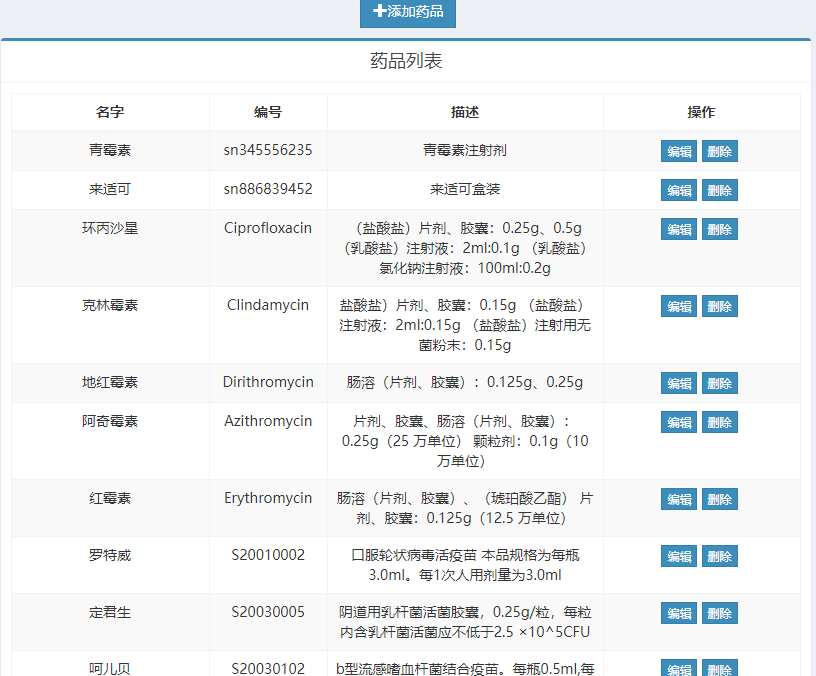
聪明的读者,你来想想这样做有什么问题呢?
对了,如果我们有大量的数据, 比如系统中存储10万种药品,这个表将会非常的长,需要后端程序从数据库中读取大量的数据,并且传递给前端。
而用户通常只需要看其中的一点点数据。这是非常大的性能浪费。
怎么解决这个问题?大家只要看看淘宝、京东这些购物网站就知道了,
方案是 分页 和 过滤 。
分页 就是 每次只读取一页的信息,返回给前端。
过滤 就是 根据用户的提供的筛选条件,只读取符合条件的部分信息。
分页
先看分页的实现。
既然要分页,那么前端发送的请求中需要携带 两个信息: 每页包含多少条记录 和 需要获取第几页
我们定义列出数据请求中 添加 2个url 参数: pagesize 和 pagenum 分别对应这两个信息。
为了实现分页 和 过滤 ,接口也做了相应的修改,修改后就是的文档:API接口文档1.2, 点击查看
Django提供了对分页的支持,具体的信息,大家可以点击这里查看其官方文档
以列出药品的代码为例, 我们可以修改 listmedicine 函数,如下
# 增加对分页的支持
from django.core.paginator import Paginator, EmptyPage
def listmedicine(request):
try:
# 返回一个 QuerySet 对象 ,包含所有的表记录
qs = Medicine.objects.values()
# 要获取的第几页
pagenum = request.params['pagenum']
# 每页要显示多少条记录
pagesize = request.params['pagesize']
# 返回一个 QuerySet 对象 ,包含所有的表记录
qs = Medicine.objects.values()
# 使用分页对象,设定每页多少条记录
pgnt = Paginator(qs, pagesize)
# 从数据库中读取数据,指定读取其中第几页
page = pgnt.page(pagenum)
# 将 QuerySet 对象 转化为 list 类型
retlist = list(page)
# total指定了 一共有多少数据
return JsonResponse({'ret': 0, 'retlist': retlist,'total': pgnt.count})
except EmptyPage:
return JsonResponse({'ret': 0, 'retlist': [], 'total': 0})
except:
return JsonResponse({'ret': 2, 'msg': f'未知错误\n{traceback.format_exc()}'})
注意,我们返回的信息,包括一页的数据, 还需要告诉前端, 符合条件的 总共有多少条记录 。为什么?
因为这样,前端可以计算出, 总共有多少页,从而正确的显示出分页界面,如下所示

这行代码 创建了 分页对象,在初始化参数里面设定每页多少条记录
返回的 分页对象 赋值给变量 pgnt。
然后:
一页的数据 就可以通过 pgnt.page(pagenum) 获取。
而总共有多少页,通过 pgnt.count 得到。
好的,我们的代码完成了,大家可以先使用 requests构建前端请求,自己测试一下。
测试代码可以是这样
import requests,pprint
# 先登陆,获取sessionid
payload = {
'username': 'byhy',
'password': '88888888'
}
response = requests.post("http://localhost/api/mgr/signin",
data=payload)
retDict = response.json()
sessionid = response.cookies['sessionid']
# 再发送列出请求,注意多了 pagenum 和 pagesize
payload = {
'action': 'list_medicine',
'pagenum': 1,
'pagesize' : 3
}
response = requests.get('http://localhost/api/mgr/medicines',
params=payload,
cookies={'sessionid': sessionid})
pprint.pprint(response.json())
我们指定了 每页3条记录,获取第一页
返回结果类似下面这样
{'ret': 0,
'retlist': [{'desc': '青霉素注射剂', 'id': 1, 'name': '青霉素', 'sn': 'sn345556235'},
{'desc': '来适可盒装', 'id': 2, 'name': '来适可', 'sn': 'sn886839452'},
{'desc': '盐酸盐片剂、胶囊', 'id': 3,'name': '环丙沙星','sn': 'Ciprofloxacin'}
],
'total': 15}
可以发现,药品总数有 15条记录,按照每页3条记录的话,返回的第一页内容就是retlist里面的信息。
大家可以修改测试代码,获取第2页的内容,对比查看一下。
过滤
我们再看过滤如何实现。
过滤 就是 根据用户的提供的筛选条件,只读取符合条件的部分信息。
比如,列出药品,需要根据 药品描述 中包含的关键字来 查询 。
而且用户可能会输入多个关键字, 比如 乳酸 和 注射液 。
这就有一个问题, 多个关键字查询 是 且 的关系 还是 或 的关系。 前者要求 药品描述 同时包含 多个关键字, 后者只需 包含其中任意一个关键字即可。
我们这里 先以 且 的关系 为例。
多条件 且关系
首先,我们需要在 列出药品的请求消息里面 添加一个参数 保存关键字信息。我们这里使用 keywords 参数。
里面包含的多个关键字之间用 空格 分开。
查询过滤条件,前面我们学过,可以通过 QuerySet 对象的 filter方法, 比如
注意,上面的 name__contains='乳酸' 表示 name 字段包含乳酸这个关键字。
Django执行该代码是,会转换为下面的SQL条件从句到数据库进行查询
如果有 多个 过滤条件, 可以继续在后面调用filter方法,比如
就等价于下面的 SQL条件从句
多个 过滤条件, 也可以多个filter方法链在一起,比如
通常在同一张表中过滤,这两种写法结果一样。
但是如果 过滤涉及到关联表,结果可能会不同,感兴趣的请点击这里,查看这篇文章
这个帖子的讲解也比较直观
多条件 或关系
上面两种写法,都是表示一种 AND 关系, 也就是要同时满足这些条件。
如果我们想表示的是 OR 的关系该怎么办呢?
这时候,可以使用 Django 里面提供 的 Q 对象 。
参考 官方文档 https://docs.djangoproject.com/en/dev/topics/db/queries/#complex-lookups-with-q-objects
了解 Q对象的详细用法
Q 对象 的初始化参数里面 携带 和 filter 语法一致的 条件,比如
如果我们查询的多个过滤条件是 或 的关系,就用 竖线 | 符号 连接多个Q对象,比如
等价于 下面的 SQL条件从句
如果我们查询的多个过滤条件是 且 的关系,也可以用 & 符号 连接多个Q对象,比如
等价于 下面的 SQL条件从句
和前面且的写法 效果相同。
利用 Q 的写法,有个独特的用途,就是过滤条件是运行时动态获取时,没法预先像下面这样写在代码中
这时,可以使用Q ,后面会讲到。
过滤类型
除了 等于、包含 这两种过滤类型, 还有 值大于、值小于、值在(列表中)等等。
还有对 过滤值的一些 特殊处理,比如 购买时间的 年、月、日 部分在某个范围内 等等,这些底层都是对应SQL的一些内置函数。
怎么实现这些过滤呢?
详情请参考官方文档这里
应用到项目代码
了解了上的知识,那么我们继续修改 listmedicine 函数,如下所示
def listmedicine(request):
try:
# .order_by('-id') 表示按照 id字段的值 倒序排列
# 这样可以保证最新的记录显示在最前面
qs = Medicine.objects.values().order_by('-id')
# 查看是否有 关键字 搜索 参数
keywords = request.params.get('keywords',None)
if keywords:
conditions = [Q(name__contains=one) for one in keywords.split(' ') if one]
query = Q()
for condition in conditions:
query &= condition
qs = qs.filter(query)
# 要获取的第几页
pagenum = request.params['pagenum']
# 每页要显示多少条记录
pagesize = request.params['pagesize']
# 使用分页对象,设定每页多少条记录
pgnt = Paginator(qs, pagesize)
# 从数据库中读取数据,指定读取其中第几页
page = pgnt.page(pagenum)
# 将 QuerySet 对象 转化为 list 类型
retlist = list(page)
# total指定了 一共有多少数据
return JsonResponse({'ret': 0, 'retlist': retlist,'total': pgnt.count})
except EmptyPage:
return JsonResponse({'ret': 0, 'retlist': [], 'total': 0})
except:
return JsonResponse({'ret': 2, 'msg': f'未知错误\n{traceback.format_exc()}'})
其中 下面这段代码
我们先构建一个空Q对象 , 表示没有任何过滤条件, 然后 循环取出过滤关键字, 使用 & 叠加过滤条件。
最后 query 就是 多个 过滤条件 同时满足 的 Q 对象
如果我们想 构建 或 的关系, 就应该这样
好的,我们可以修改测试代码,加上过滤条件,再测试一下
import requests,pprint
payload = {
'username': 'byhy',
'password': '88888888'
}
response = requests.post("http://localhost/api/mgr/signin",
data=payload)
retDict = response.json()
sessionid = response.cookies['sessionid']
# 再发送列出请求,注意多了 keywords
payload = {
'action': 'list_medicine',
'pagenum': 1,
'pagesize' : 3,
'keywords' : '乳酸 注射液'
}
response = requests.get('http://localhost/api/mgr/medicines',
params=payload,
cookies={'sessionid': sessionid})
pprint.pprint(response.json())
这里我们加上 删除订单的代码,如下
def deleteorder(request):
# 获取订单ID
oid = request.params['id']
try:
one = Order.objects.get(id=oid)
with transaction.atomic():
# 一定要先删除 OrderMedicine 里面的记录
OrderMedicine.objects.filter(order_id=oid).delete()
# 再删除订单记录
one.delete()
return JsonResponse({'ret': 0, 'id': oid})
except Order.DoesNotExist:
return JsonResponse({
'ret': 1,
'msg': f'id 为`{oid}`的订单不存在'
})
except:
err = traceback.format_exc()
return JsonResponse({'ret': 1, 'msg': err})
集成前端
我们的前端开发人员也没有闲着,他们根据接口的变动,修改代码的同时,也大大的修改了一下界面,如下。
是不是好看很多了 :)
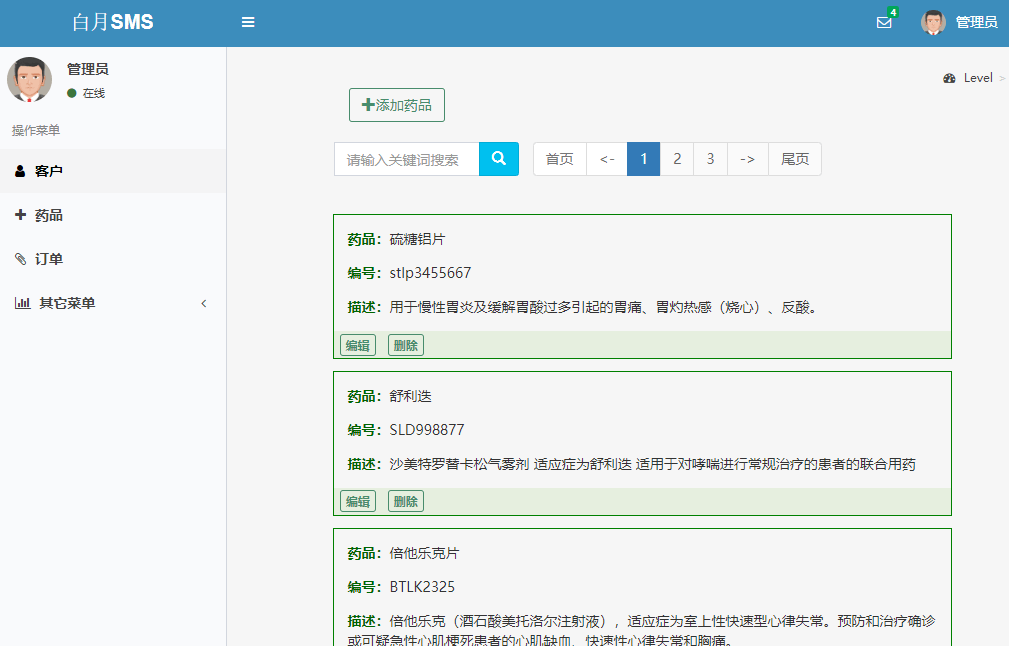
我们后端开发者可以把前端发布的包拿过来进行集成测试。
在如下百度网盘中的 bysms_front_v1.5.zip
百度网盘链接:https://pan.baidu.com/s/1nUyxvq6IYykBNtPUf4Ho6w
提取码:9w2u
目前为止,我们项目代码,在如下百度网盘中的 bysms_12.zip
百度网盘链接:https://pan.baidu.com/s/1nUyxvq6IYykBNtPUf4Ho6w
提取码:9w2u