缓存
开发服务端系统, 性能 始终是重中之重。
怎样提高系统性能, 在 单位时间内 处理更多的请求呢?
那么我们就需要思考:系统 处理 单个请求的代码主要做哪些事情,其中哪些是最耗费时间的。
处理一个请求,服务通常有如下事情:
-
接收HTTP请求消息,解析请求消息为数据对象
-
根据业务逻辑的需要,去访问数据库(增删改查)
-
处理结果转化为HTTP响应消息给 客户端
这里面哪个是最耗费时间的呢?
通常是第二步,数据库操作。
因为 数据库操作 涉及到 数据库服务处理请求,读写硬盘数据。往往比较耗时。
所以对 数据库操作的 优化 往往是提高系统性能的 首选目标。
数据库操作可以大体分为 读、写 两种。
读 就是查询数据, 写 就是 添加、修改、删除数据。
这节课程,我们重点讲解 通过 缓存 的方法来 优化对数据库 读操作 的 性能。
缓存的原理
缓存是怎么提高数据库读操作的性能的?
主要是把 需要读取的数据库数据 存放到内存 中, 下次客户端请求读取同样的数据,可以直接从内存中读取。
大家知道,程序访问内存的速度要比访问数据库快很多, 因为避免了从硬盘读取表记录的操作。 特别是当一个读操作要涉及到多张表的联合查询,或者这些表比较大,就会非常耗时。
Redis
要缓存数据到内存, 我们可以使用多种方案。
最简单的,我们可以直接使用Python内置的 字典对象缓存数据。
但是这种方法有个弊端: 不支持 分布式计算
当我们的网站服务量巨大时,为了提高处理能力,会部署服务到多台主机。
如果每台主机都使用 本机内存 缓存数据,有两个问题:
-
资源浪费,每台主机都可能用内存缓存着同样的数据。
-
更重要的,当某个主机发现缓存数据需要更新时(比如修改了数据),要通知其他节点一起更新,比较麻烦, 还要防止 数据同步前 可能不同节点给出的数据不一致的问题。
所以,我们应该使用一个类似 内存数据库 的 服务系统 ,提供统一的缓存服务
Redis 和 Memcached 是目前两种主流的缓存服务方案。
Redis 目前更受欢迎,我们教程就使用它。
Linux 上安装 Redis
Redis对Linux的支持是最主流的。
实战班学员前面锻炼过 Linux系统的使用,推荐Linux上安装Redis。
Ubuntu 或者 Debian 可以 使用 Apt 安装,
要执行的命令如下
sudo apt-get install lsb-release curl gpg
curl -fsSL https://packages.redis.io/gpg | sudo gpg --dearmor -o /usr/share/keyrings/redis-archive-keyring.gpg
sudo chmod 644 /usr/share/keyrings/redis-archive-keyring.gpg
echo "deb [signed-by=/usr/share/keyrings/redis-archive-keyring.gpg] https://packages.redis.io/deb $(lsb_release -cs) main" | sudo tee /etc/apt/sources.list.d/redis.list
sudo apt-get update
sudo apt-get install redis
装好后,redis服务自动启动。 如果你发现没有,可以通过下面的命令启动
如果你需要让这个Redis服务给非本机的程序(比如Django) 使用,就应该把配置文件中绑定的地址 从本机loop地址 127.0.0.1 改为 0.0.0.0
找到配置文件 /etc/redis/redis.conf 中,如下地方
改为
缺省情况下,Redis服务配置是无密码认证的。为了安全起见,这时是只允许本地客户端连接的。
如果你确保远程主机访问没有安全问题(比如只有本地局域网可以访问该主机),你想无需密码认证,就让远程客户端访问, 修改配置文件中如下地方
改为
当然如果本机有防火墙软件,别忘了打开防火墙,开放 6379 端口
最后,执行下面的命令重启 Redis服务,使修改后的配置生效。
Windows上安装 Redis
通常我们产品运行都是Linux,但是开发环境,我们往往都是Windows,为了方便,可以在开发环境里面安装一个 Windows版 的 Redis
点击下面百度网盘链接,下载 Windows 版 Redis 压缩包
链接:https://pan.baidu.com/s/1UyJ-eDypTuDWhvvI7CMgiQ?pwd=1111 提取码:1111
下载后解压,进入到目录 Redis-x64-3.2.100 ,运行里面的 redis-server.exe 就启动了 Redis服务。
Redis使用
Redis是一个数据仓库服务,这个仓库里面可以存储很多 数据对象
存储的每个数据对象都有一个key,根据这个key,可以找到这个对象。
要添加一个数据对象,必须为这个数据对象指定一个key,就像指定一个房间号
如下图
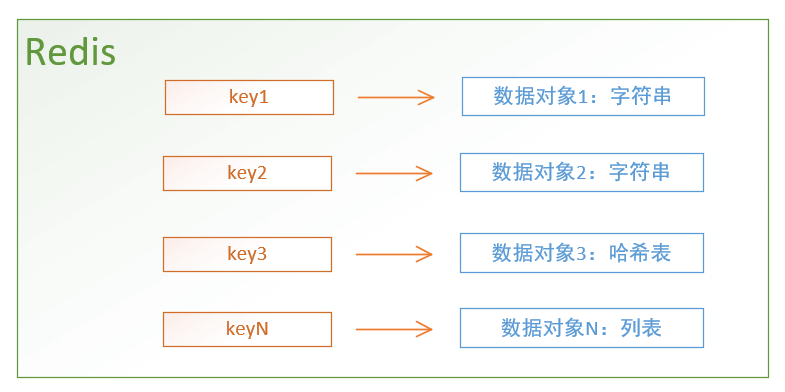
注意:Redis key 对应的value 支持 多种类型 的数据对象。可以是字符串、列表、哈希对象(类似Python中的字典)
这一点和其他 键值对(key-value)系统不同。比如memcached的值只能是字符串。
官方客户端
和 MySQL 一样,Redis 也是一个数据 服务 系统,是为客户端程序提供服务的。
客户端程序和 Redis服务 之间也是通过网络连接传递操作请求,和返回响应数据的。
按照上面讲述的方法,安装 Redis时,也会安装一个官方Redis 客户端。
Windows下面是一个exe可执行程序: redis-cli.exe , 双击它即可运行
Linux 下面执行命令 redis-cli 即可运行。
Redis 数据库
和 MySQL 一样,Redis 里面也包含了多个数据库,以数字进行编号,通常 Redis 自动创建 16个 编号 从 0 到 15 的数据库。
缺省连接是编号为 0 的数据库。
可以使用命令 select 来选择使用哪个Redis数据库,
比如下面的命令就选择编号为1的数据库
存入string对象
根据存入数据对象 类型 的不同,我们需要使用不同的Redis命令,
假设,我们要缓存一个用户表里面的数据,可以为key指定格式 user:<id>
比如,
id为1的用户,key就是 user:1
id为2000的用户,key就是 user:2000
如果我们要存入 Redis的value是字符串对象,就使用客户端命令 set
比如,要为id 为2000 的用户存入等级值 33,就执行如下命令
要从Redis获取key为 user:2000 的值,就执行,如下命令
查询有哪些key
要查询系统中有哪些key,可以使用命令keys,可以使用通配符 *
比如,要查询以 med 开头的key,可以这样
删除数据
如果要删除一个key和其对应的对象,可以使用命令del
存入哈希对象
如果我们要存入 Redis的对象比较复杂,比如用户信息,包括等级、金币、姓名等等,
可以使用哈希(Hash)对象,它类似Python中的字典。
Redis 哈希对象的每个字段 ,术语称之为 field
存入Hashes,就使用客户端命令 hmset 或者 hset ,比如
注意最后存入的是其实是bytes字节,所以其中的中文字符会被进行相应的编码,比如utf8或者gbk
具体使用哪种编码,由客户端程序决定。
要获取Hash里面的对象,使用 hgetall, 如下
> hgetall user:2001
1) "level"
2) "10"
3) "coin"
4) "1977"
5) "name"
6) "\xe7\x99\xbd\xe6\x9c\x88\xe9\xbb\x91\xe7\xbe\xbd"
注意这里,name字段的值被utf8编码了,客户端程序在使用时根据需要进行相应解码。
如果只要获取 hash对象的一个字段,可以使用 hget,比如
注意, hmset 是存入多个字段值, 如果只要存入(或者修改)一个字段值,就用可以使用hset
比如要修改 coin的值为 2000,
再获取,就可以发现coin值相应的改变了
既然 Hash 本身就是一个字典,我们通常还有一种方案:
就是把 整个用户表 都直接放入 一个hash 里面
可以给这个hash对应的对象 起一个key名为 usertable 。
然后就可以这样
> hmset usertable u2001 id:2001|level:10|coin:1977|name:白月黑羽1
> hmset usertable u2002 id:2002|level:13|coin:1927|name:白月黑羽2
OK
然后,要获取一个用户的信息,就可以这样
> hget usertable u2002
"id:2002|level:13|coin:1927|name:\xe7\x99\xbd\xe6\x9c\x88\xe9\xbb\x91\xe7\xbe\xbd2"
两种方案,各有优缺点。
前者利于修改单个field的值,但是容易造成巨大的key数量, 污染 全局的key名字空间
后者正好相反, 没法修改单个field的值,要改只能一起改。 但是全局的key名字空间就比较清爽。
具体采用哪种方案存储,开发者根据当前情况 自己权衡。
Django项目缓存配置
首先,执行下面的命令安装 一个库 django-redis
然后在 Django 的项目配置文件 settings.py 中,添加如下的缓存配置项
CACHES = {
"default": {
"BACKEND": "django_redis.cache.RedisCache",
"LOCATION": "redis://127.0.0.1:6379/1",
"OPTIONS": {
"CLIENT_CLASS": "django_redis.client.DefaultClient",
}
}
}
上面的这段配置可以放在数据库 DATABASES 配置项的下方。LOCATION 配置项最后的数字1 是 DB number,指定redis的数据库号
代码使用缓存
不是任何数据库的数据都应该使用缓存。
应该符合如下两条规则:
- 频繁读取的数据
否则使用缓存,性能提升也不大
-
较少变动的数据
每次数据改变后,缓存都要重新读取。如果经常变动,反而会带来性能的下降。
假设,我们的 bysms系统中,药品数据是 频繁读取,且较少变动的。
我们可以 在处理 列出药品 的API接口 的代码中,把 数据库读出的内容 进行 缓存。
这里,我们采用上面的缓存方案二,把所有的 列出药品都放在一个哈希对象中。
首先,我们需要为 列出药品的缓存 创建一个key,名字为 medicinelist
因为我们将来会有很多种类型的数据要缓存,它们有不同的key,所以建议统一放在配置文件 settings.py 中,如下
# 记录全局的缓存key,防止重复
class CK:
# 列出药品 的 缓存 key
MedineList = 'list_medicine'
# 列出客户 的 缓存 key
CustomerList = 'list_customer'
这样的好处是,放在一起,如果有重复的key名,比较容易发现
然后,在 mgr/medicine.py 文件开头处,进行如下修改
from django_redis import get_redis_connection
from bysms import settings
import json
# 获取一个和Redis服务的连接
rconn = get_redis_connection("default")
def listmedicine(request):
try:
# 查看是否有 关键字 搜索 参数
keywords = request.params.get('keywords',None)
# 要获取的第几页
pagenum = request.params['pagenum']
# 每页要显示多少条记录
pagesize = request.params['pagesize']
# 先看看缓存中是否有
cacheField = f"{pagesize}|{pagenum}|{keywords}" # 缓存 field
cacheObj = rconn.hget(settings.CK.MedineList,
cacheField)
# 缓存中有,需要反序列化
if cacheObj:
print('缓存命中')
retObj = json.loads(cacheObj)
# 如果缓存中没有,再去数据库中查询
else:
print('缓存中没有')
# 返回一个 QuerySet 对象 ,包含所有的表记录
qs = Medicine.objects.values().order_by('-id')
if keywords:
conditions = [Q(name__contains=one) for one in keywords.split(' ') if one]
query = Q()
for condition in conditions:
query &= condition
qs = qs.filter(query)
# 使用分页对象,设定每页多少条记录
pgnt = Paginator(qs, pagesize)
# 从数据库中读取数据,指定读取其中第几页
page = pgnt.page(pagenum)
# 将 QuerySet 对象 转化为 list 类型
retlist = list(page)
retObj = {'ret': 0, 'retlist': retlist,'total': pgnt.count}
# 存入缓存
rconn.hset(settings.CK.MedineList,
cacheField,
json.dumps(retObj))
# total指定了 一共有多少数据
return JsonResponse(retObj)
except EmptyPage:
return JsonResponse({'ret': 0, 'retlist': [], 'total': 0})
except:
print(traceback.format_exc())
return JsonResponse({'ret': 2, 'msg': f'未知错误\n{traceback.format_exc()}'})
这样,我们就确保了,处理列出药品的请求时,优先从缓存中读取,如果没有再从数据库读取。
并且数据库读取到数据后,存入缓存,这样下次同样的请求就可以从缓存中获取数据了。
缓存数据更新
是不是有了上面的代码就万事大吉了呢?
使用缓存一定要注意一个重点:缓存数据的更新。
比如:如果后面我们对药品数据做出了添加、修改、删除的操作,那么缓存里面的数据就很有可能和数据库里面的不一致。
所以,一旦数据被更改,就要相应的更新缓存。
如果更新缓存特别麻烦,更简单的方法是:直接删除对应的缓存数据。这样下次请求,缓存中没有了数据,还是会从数据库读取,这样读取的就是最新数据,然后再缓存最新的数据。
所以我们可以修改 添加、列出、删除药品的代码,如下
def addmedicine(request):
info = request.params['data']
# 从请求消息中 获取要添加客户的信息
# 并且插入到数据库中
medicine = Medicine.objects.create(name=info['name'] ,
sn=info['sn'] ,
desc=info['desc'])
# 同时删除整个 medicine 缓存数据
# 因为不知道这个添加的药品会影响到哪些列出的结果
# 只能全部删除
rconn.delete(settings.CK.MedineList)
return JsonResponse({'ret': 0, 'id':medicine.id})
def modifymedicine(request):
# 从请求消息中 获取修改客户的信息
# 找到该客户,并且进行修改操作
medicineid = request.params['id']
newdata = request.params['newdata']
try:
# 根据 id 从数据库中找到相应的客户记录
medicine = Medicine.objects.get(id=medicineid)
except Medicine.DoesNotExist:
return {
'ret': 1,
'msg': f'id 为`{medicineid}`的药品不存在'
}
if 'name' in newdata:
medicine.name = newdata['name']
if 'sn' in newdata:
medicine.sn = newdata['sn']
if 'desc' in newdata:
medicine.desc = newdata['desc']
# 注意,一定要执行save才能将修改信息保存到数据库
medicine.save()
# 同时删除整个 medicine 缓存数据
# 因为不知道这个修改的药品会影响到哪些列出的结果
# 只能全部删除
rconn.delete(settings.CK.MedineList)
return JsonResponse({'ret': 0})
def deletemedicine(request):
medicineid = request.params['id']
try:
# 根据 id 从数据库中找到相应的药品记录
medicine = Medicine.objects.get(id=medicineid)
except Medicine.DoesNotExist:
return {
'ret': 1,
'msg': f'id 为`{medicineid}`的客户不存在'
}
# delete 方法就将该记录从数据库中删除了
medicine.delete()
# 同时删除整个 medicine 缓存数据
# 因为不知道这个删除的药品会影响到哪些列出的结果
# 只能全部删除
rconn.delete(settings.CK.MedineList)
return JsonResponse({'ret': 0})
这样完整的缓存方案就实现了。
大家可以启动Redis服务,再次运行web服务,看看访问列出药品的页面,是不是心理上是不是会感觉快点了呢:)
目前为止,我们项目代码,在如下百度网盘中的 bysms_13.zip
百度网盘链接:https://pan.baidu.com/s/1nUyxvq6IYykBNtPUf4Ho6w
提取码:9w2u