文件读写
本文读写的文件,都是指 文本文件 , 至于 视频、图片等类型的文件,它们有各自的不同的文件数据格式,不在这里讲述。
我们开发程序,经常需要从文本文件中读入信息,比如从日志文件中读取日志,从而分析数据信息;
也经常需要写入文本信息到文件中,比如写入操作信息到日志文件中。
在python语言中,我们要读写文本文件, 首先通过内置函数open 打开一个文件。
open函数会返回一个对象,我们可以称之为文件对象。
这个返回的文件对象就包含读取文本内容和写入文本内容的方法。
前面的课程我们刚刚学过,要写入字符串到文件中,需要先将字符串编码为字节串。
而从文本文件中读取的文本信息都是字节串,要进行处理之前,必须先将字节串解码为字符串。
文件的打开,分为 文本模式 和 二进制模式。
文本模式
通常,对文本文件,都是以文本模式打开。
文本模式打开文件后,我们的程序读取到的内容都是字符串对象,写入文件时传入的也是字符串对象。
open函数的参数
要读写文件,首先要通过内置函数open 打开文件,获得文件对象。
函数open的参数如下
open(
file,
mode='r',
buffering=-1,
encoding=None,
errors=None,
newline=None,
closefd=True,
opener=None
)
其中下面这3个参数是我们常用的。
-
参数 file
file参数指定了要打开文件的路径。
可以是相对路径,比如 'log.txt', 就是指当前工作目录下面的log.txt 文件 也可以是绝对路径,比如 'd:\project\log\log.txt',
-
参数 mode
mode参数指定了文件打开的
模式,打开文件的模式 决定了可以怎样操作文件。常用的打开模式有
-
r 只读文本模式打开,这是最常用的一种模式
-
w 只写文本模式打开
-
a 追加文本模式打开
如果我们要 读取文本文件内容到字符串对象中 , 就应该使用 r 模式。
我们可以发现mode参数的缺省值 就是 'r' 。
就是说,调用open函数时,如果没有指定参数mode的值,那么该参数就使用缺省值 'r',表示只读打开。
如果我们要 创建一个新文件写入内容,或者清空某个文本文件重新写入内容, 就应该使用 'w' 模式。
如果我们要 从某个文件末尾添加内容, 就应该使用 'a' 模式。
-
-
参数 encoding
encoding 参数指定了读写文本文件时,使用的 字符编解码 方式。
调用open函数时,如果传入了encoding参数值:
后面调用write写入字符串到文件中,open函数会使用指定encoding编码为字节串; 后面调用read从文件中读取内容,open函数会使用指定encoding解码为字符串对象如果调用的时候没有传入encoding参数值,open函数会使用系统缺省字符编码方式。 比如在中文的Windows系统上,就是使用cp936(就是gbk编码)。
建议大家编写代码 读写文本文件时,都指定该参数的值。
写文件示例
下面的示例代码写入文本内容到文件中, 大家可以拷贝执行一下。
# 指定编码方式为 utf8
f = open('tmp.txt','w',encoding='utf8')
# write方法会将字符串编码为utf8字节串写入文件
f.write('白月黑羽:祝大家好运气')
# 文件操作完毕后, 使用close 方法关闭该文件对象
f.close()
上面使用的是utf8编码写入文件的。
运行一下,我们用notepad++文本编辑器(notepad++可以百度搜索下载)打开该文件。
可以发现该文件确实是utf8编码。
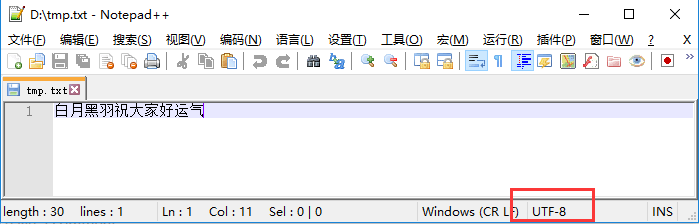
如果我们换成用gbk编码字符串写入到文件中
# 指定编码方式为 gb2312
f = open('tmp.txt','w',encoding='gb2312')
# write方法会将字符串编码为gb2312字节串存入文件中
f.write('白月黑羽:祝大家好运气')
# 文件操作完毕后, 使用close 方法关闭该文件对象
f.close()
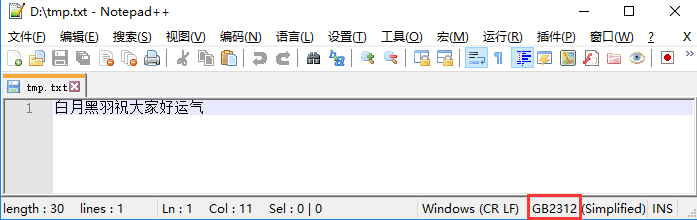
可以发现该文件确实是gb2312编码。
mode参数为'w',表示要覆盖写文件。 这就意味着,如果原来文件中有内容, 该模式打开文件后,文件中所有的内容都会被 !!!删除掉!!!
所以要特别的小心。
有的场合下,我们需要在文件末尾添加新的内容,而不是删除掉原来的内容重新写。比如写日志文件,在重新启动系统的时候,需要接着在原来的日志文件后面添加新的内容。
这时,我们可以用追加模式 a 打开文件。
例如
# a 表示 追加模式 打开文件
f = open('tmp.txt','a',encoding='gb2312')
f.write('白月黑羽再次祝大家 :good luck')
f.close()
读文件示例
下面这段示例代码,实现的功能是:从前面的代码生成的文本文件中,读出内容到字符串对象中,并且截取出其中的名字部分, 大家可以拷贝执行一下。
# 指定编码方式为 gbk,gbk编码兼容gb2312
f = open('tmp.txt','r',encoding='gbk')
# read 方法会在读取文件中的原始字节串后, 根据上面指定的gbk解码为字符串对象返回
content = f.read()
# 文件操作完毕后, 使用close 方法关闭该文件对象
f.close()
# 通过字符串的split方法获取其中用户名部分
name = content.split(':')[0]
print(name)
注意点
read函数有参数size,读取文本文件的时候,用来指定这次读取多少个字符。 如果不传入该参数,就是读取文件中所有的内容。
大家可以创建一个文本文件,内容如下
我们可以这样读取该文本文件
# 因为是读取文本文件的模式, 可以无须指定 mode参数
# 因为都是 英文字符,基本上所有的编码方式都兼容ASCII,可以无须指定encoding参数
f = open('tmp.txt')
tmp = f.read(3) # read 方法读取3个字符
print(tmp) # 返回3个字符的字符串 'hel'
tmp = f.read(3) # 继续使用 read 方法读取3个字符
print(tmp) # 返回3个字符的字符串 'lo\n' 换行符也是一个字符
tmp = f.read() # 不加参数,读取剩余的所有字符
print(tmp) # 返回剩余字符的字符串 'cHl0aG9uMy52aXAgYWxsIHJpZ2h0cyByZXNlcnZlZA=='
# 文件操作完毕后, 使用close 方法关闭该文件对象
f.close()
读取文本文件内容的时候,通常还会使用readlines方法,该方法会返回一个列表。 列表中的每个元素依次对应文本文件中每行内容。
但是这种方法,列表的每个元素对应的字符串 最后有一个换行符。 如果你不想要换行符,可以使用字符串对象的splitlines方法
f = open('tmp.txt')
content = f.read() # 读取全部文件内容
f.close()
# 将文件内容字符串 按换行符 切割 到列表中,每个元素依次对应一行
linelist = content.splitlines()
for line in linelist:
print(line)
二进制(字节)模式
不知道大家有没有注意,前面我们讲的打开文件,读写文件。都强调这是 文本文件。
前面我们打开文件都是 文本模式 打开,可能大家还听说过 二进制模式 打开文件。
其实就文件存储的底层来说,不管什么类型的文件(文本、视频、图片、word、excel等),存储的都是字节,不存在文本和二进制的区别,可以说都是二进制。
所以 二进制模式 这个名词容易引起大家的误解, 如果让我来翻译,我觉得叫做 字节模式 更好。
读写文件底层操作读写的 都是字节。
以文本模式打开文件后, 后面的读写文件的方法(比如 read,write等),底层实现都会自动的进行 字符串(对应Python的string对象)和字节串(对应Python的bytes对象) 的转换。
我们可以指定open函数的mode参数,直接读取原始的 二进制 字节串 到一个bytes对象中。
大家可以写入字符串 白月黑羽 到一个文件中,保存时使用utf8编码
然后我们这样运行下面的代码
# mode参数指定为rb 就是用二进制读的方式打开文件
f = open('tmp.txt','rb')
content = f.read()
f.close()
# 由于是 二进制方式打开,所以得到的content是 字节串对象 bytes
# 内容为 b'\xe7\x99\xbd\xe6\x9c\x88\xe9\xbb\x91\xe7\xbe\xbd'
print(content)
# 该对象的长度是字节串里面的字节个数,就是12,每3个字节对应一个汉字的utf8编码
print(len(content))
以二进制方式写数据到文件中,传给write方法的参数不能是字符串,只能是bytes对象
比如
# mode参数指定为 wb 就是用二进制写的方式打开文件
f = open('tmp.txt','wb')
content = '白月黑羽祝大家好运连连'
# 二进制打开的文件, 写入的参数必须是bytes类型,
# 字符串对象需要调用encode进行相应的编码为bytes类型
f.write(content.encode('utf8'))
f.close()
如果你想在代码中 直接用数字 表示字节串的内容,并写入文件,可以这样
既然任何文件都可以以字节方式进行读取 和写入, 那么我来考考你们。
如何字节实现一个简单的文件拷贝功能呢?
比如实现一个函数,有两个参数,第一个参数是源文件路径,第二个参数是拷贝生成的目标文件路径。
可以像下面的代码这样
def fileCopy(srcPath,destPath):
srcF = open(srcPath,'rb')
content = srcF.read()
srcF.close()
destF = open(destPath,'wb')
destF.write(content)
destF.close()
fileCopy('1.png','1copy.png')
with 语句
如果我们开发的程序 在进行文件读写之后,忘记使用close方法关闭文件, 就可能造成意想不到的问题。
我们可以使用with 语句 打开文件,像这样,就不需要我们调用close方法关闭文件。 Python解释器会帮我们调用文件对象的close方法。
如下
# open返回的对象 赋值为 变量 f
with open('tmp.txt') as f:
linelist = f.readlines()
for line in linelist:
print(line)
对文件的操作都放在with下面的缩进的代码块中。
写入缓冲
我们来看下面的代码
f = open('tmp.txt','w',encoding='utf8')
f.write('白月黑羽:祝大家好运气')
# 等待 30秒,再close文件
import time
time.sleep(30)
f.close()
执行该程序时,执行完写入文件内容后,会等待30秒,再关闭文件对象。
在这30秒还没有结束的时候,如果你打开 tmp.txt, 将会惊奇的发现,该文件中啥内容也没有!!!
为什么?
不是刚刚执行过下面的代码吗?
原来,我们执行write方法写入字节到文件中的时候,其实只是把这个请求提交给 操作系统。
操作系统为了提高效率,通常并不会立即把内容写到存储文件中, 而是写入内存的一个 缓冲区 。
等缓冲区的内容堆满之后,或者程序调用close 关闭文件对象的时候,再写入到文件中。
如果你确实希望,在调用write之后,立即把内容写到文件里面,可以使用 文件对象的 flush方法。
如下所示
f = open('tmp.txt','w',encoding='utf8')
f.write('白月黑羽:祝大家好运气')
# 立即把内容写到文件里面
f.flush()
# 等待 30秒,再close文件
import time
time.sleep(30)
f.close()
这样再执行程序,在等待的30秒期间,你打开文件,发现里面已经有写入的字符串 "白月黑羽:祝大家好运气" 了。